本文共 63802 字,大约阅读时间需要 212 分钟。
1-Hello World
python的语法逻辑完全靠缩进,建议缩进4个空格。
如果是顶级代码,那么必须顶格书写,哪怕只有一个空格也会有语法错误。 下面示例中,满足if条件要输出两行内容,这两行内容必须都缩进,而且具有相同的缩进级别print('hello world!')if 3 > 0: print('OK') print('yes')x = 3; y = 4 # 不推荐,还是应该写成两行print(x + y) 2-print
print('hello world!')print('hello', 'world!') # 逗号自动添加默认的分隔符:空格print('hello' + 'world!') # 加号表示字符拼接print('hello', 'world', sep='***') # 单词间用***分隔print('#' * 50) # *号表示重复50遍print('how are you?', end='') # 默认print会打印回车,end=''表示不要回车 3-基本运算
运算符可以分为:算术运算符、比较运算符和逻辑运算符。优先级是:算术运算符>比较运算符>逻辑运算符。不过呢,开始没背下来优先级,最好使用括号。这样不用背,也增加了代码的可读性
print(5 / 2) # 2.5print(5 // 2) # 丢弃余数,只保留商print(5 % 2) # 求余数print(5 ** 3) # 5的3次方print(5 > 3) # 返回Trueprint(3 > 5) # 返回Falseprint(20 > 10 > 5) # python支持连续比较print(20 > 10 and 10 > 5) # 与上面相同含义print(not 20 > 10) # False注意:True和False是关键字,区分大小写
4-input
number = input("请输入数字: ") # input用于获取键盘输入print(number)print(type(number)) # input获得的数据是字符型print(number + 10) # 报错,不能把字符和数字做运算print(int(number) + 10) # int可将字符串10转换成数字10print(number + str(10)) # str将10转换为字符串后实现字符串拼接 5-输入输出基础练习
username = input('username: ')print('welcome', username) # print各项间默认以空格作为分隔符print('welcome ' + username) # 注意引号内最后的空格 6-字符串使用基础
python中,单双引号没有区别,表示一样的含义
sentence = 'tom\'s pet is a cat' # 单引号中间还有单引号,可以转义sentence2 = "tom's pet is a cat" # 也可以用双引号包含单引号sentence3 = "tom said:\"hello world!\""sentence4 = 'tom said:"hello world"'三个连续的单引号或双引号,可以保存输入格式,允许输入多行字符串words = """helloworldabcd"""print(words)py_str = 'python'len(py_str) # 取长度py_str[0] # 第一个字符'python'[0]py_str[-1] # 最后一个字符# py_str[6] # 错误,下标超出范围py_str[2:4] # 切片,起始下标包含,结束下标不包含py_str[2:] # 从下标为2的字符取到结尾py_str[:2] # 从开头取到下标是2之前的字符py_str[:] # 取全部py_str[::2] # 步长值为2,默认是1py_str[1::2] # 取出yhnpy_str[::-1] # 步长为负,表示自右向左取py_str + ' is good' # 简单的拼接到一起py_str * 3 # 把字符串重复3遍't' in py_str # True'th' in py_str # True'to' in py_str # False'to' not in py_str # True
7-列表基础
列表也是序列对象,但它是容器类型,列表中可以包含各种数据
alist = [10, 20, 30, 'bob', 'alice', [1,2,3]]len(alist)alist[-1] # 取出最后一项alist[-1][-1] # 因为最后一项是列表,列表还可以继续取下标[1,2,3][-1] # [1,2,3]是列表,[-1]表示列表最后一项alist[-2][2] # 列表倒数第2项是字符串,再取出字符下标为2的字符alist[3:5] # ['bob', 'alice']10 in alist # True'o' in alist # False100 not in alist # Truealist[-1] = 100 # 修改最后一项的值alist.append(200) # 向列表中追加一项
8-元组基础
元组与列表基本上是一样的,只是元组不可变,列表可变
atuple = (10, 20, 30, 'bob', 'alice', [1,2,3])len(atuple)10 in atupleatuple[2]atuple[3:5]# atuple[-1] = 100 # 错误,元组是不可变的
9-字典基础
字典是key-value(键-值)对形式的,没有顺序,通过键取出值
adict = {'name': 'bob', 'age': 23}len(adict)'bob' in adict # False'name' in adict # Trueadict['email'] = 'bob@tedu.cn' # 字典中没有key,则添加新项目adict['age'] = 25 # 字典中已有key,修改对应的value 10-基本判断
单个的数据也可作为判断条件。
任何值为0的数字、空对象都是False,任何非0数字、非空对象都是Trueif 3 > 0: print('yes') print('ok')if 10 in [10, 20, 30]: print('ok')if -0.0: print('yes') # 任何值为0的数字都是Falseif [1, 2]: print('yes') # 非空对象都是Trueif ' ': print('yes') # 空格字符也是字符,条件为True 11-条件表达式、三元运算符
a = 10b = 20if a < b: smaller = aelse: smaller = bprint(smaller)s = a if a < b else b # 和上面的if-else语句等价print(s)
12-判断练习:用户名和密码是否正确
import getpass # 导入模块username = input('username: ')# getpass模块中,有一个方法也叫getpasspassword = getpass.getpass('password: ')if username == 'bob' and password == '123456': print('Login successful')else: print('Login incorrect') 13-猜数:基础实现
import randomnum = random.randint(1, 10) # 随机生成1-10之间的数字answer = int(input('guess a number: ')) # 将用户输入的字符转成整数if answer > num: print('猜大了')elif answer < num: print('猜小了')else: print('猜对了')print('the number:', num) 14-成绩分类1
score = int(input('分数: '))if score >= 90: print('优秀')elif score >= 80: print('好')elif score >= 70: print('良')elif score >= 60: print('及格')else: print('你要努力了') 15-成绩分类2
score = int(input('分数: '))if score >= 60 and score < 70: print('及格')elif 70 <= score < 80: print('良')elif 80 <= score < 90: print('好')elif score >= 90: print('优秀')else: print('你要努力了') 16-石头剪刀布
import randomall_choices = ['石头', '剪刀', '布']computer = random.choice(all_choices)player = input('请出拳: ')print('Your choice:', player, "Computer's choice:", computer)print("Your choice: %s, Computer's choice: %s" % (player, computer))if player == '石头': if computer == '石头': print('平局') elif computer == '剪刀': print('You WIN!!!') else: print('You LOSE!!!')elif player == '剪刀': if computer == '石头': print('You LOSE!!!') elif computer == '剪刀': print('平局') else: print('You WIN!!!')else: if computer == '石头': print('You WIN!!!') elif computer == '剪刀': print('You LOSE!!!') else: print('平局') 17-改进的石头剪刀布
import randomall_choices = ['石头', '剪刀', '布']win_list = [['石头', '剪刀'], ['剪刀', '布'], ['布', '石头']]prompt = """(0) 石头(1) 剪刀(2) 布请选择(0/1/2): """computer = random.choice(all_choices)ind = int(input(prompt))player = all_choices[ind]print("Your choice: %s, Computer's choice: %s" % (player, computer))if player == computer: print('\033[32;1m平局\033[0m')elif [player, computer] in win_list: print('\033[31;1mYou WIN!!!\033[0m')else: print('\033[31;1mYou LOSE!!!\033[0m') 18-猜数,直到猜对
import randomnum = random.randint(1, 10)running = Truewhile running: answer = int(input('guess the number: ')) if answer > num: print('猜大了') elif answer < num: print('猜小了') else: print('猜对了') running = False 19-猜数,5次机会
import randomnum = random.randint(1, 10)counter = 0while counter < 5: answer = int(input('guess the number: ')) if answer > num: print('猜大了') elif answer < num: print('猜小了') else: print('猜对了') break counter += 1else: # 循环被break就不执行了,没有被break才执行 print('the number is:', num) 20-while循环,累加至100
因为循环次数是已知的,实际使用时,建议用for循环
sum100 = 0counter = 1while counter < 101: sum100 += counter counter += 1print(sum100)
21-while-break
break是结束循环,break之后、循环体内代码不再执行
while True: yn = input('Continue(y/n): ') if yn in ['n', 'N']: break print('running...') 22-while-continue
计算100以内偶数之和。
continue是跳过本次循环剩余部分,回到循环条件处sum100 = 0counter = 0while counter < 100: counter += 1 # if counter % 2: if counter % 2 == 1: continue sum100 += counterprint(sum100)
23-for循环遍历数据对象
astr = 'hello'alist = [10, 20, 30]atuple = ('bob', 'tom', 'alice')adict = {'name': 'john', 'age': 23}for ch in astr: print(ch)for i in alist: print(i)for name in atuple: print(name)for key in adict: print('%s: %s' % (key, adict[key])) 24-range用法及数字累加
range(10) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>> list(range(10))range(6, 11) # [6, 7, 8, 9, 10]range(1, 10, 2) # [1, 3, 5, 7, 9]range(10, 0, -1) # [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]sum100 = 0for i in range(1, 101): sum100 += iprint(sum100)
25-列表实现斐波那契数列
列表中先给定两个数字,后面的数字总是前两个数字之和
fib = [0, 1]for i in range(8): fib.append(fib[-1] + fib[-2])print(fib)
26-九九乘法表
for i in range(1, 10): for j in range(1, i + 1): print('%s*%s=%s' % (j, i, i * j), end=' ') print()# i=1 ->j: [1]# i=2 ->j: [1,2]# i=3 ->j: [1,2,3]由用户指定相乘到多少n = int(input('number: '))for i in range(1, n + 1): for j in range(1, i + 1): print('%s*%s=%s' % (j, i, i * j), end=' ') print() 27-逐步实现列表解析
# 10+5的结果放到列表中[10 + 5]# 10+5这个表达式计算10次[10 + 5 for i in range(10)]# 10+i的i来自于循环[10 + i for i in range(10)][10 + i for i in range(1, 11)]# 通过if过滤,满足if条件的才参与10+i的运算[10 + i for i in range(1, 11) if i % 2 == 1][10 + i for i in range(1, 11) if i % 2]# 生成IP地址列表['192.168.1.%s' % i for i in range(1, 255)]
28-三局两胜的石头剪刀布
in_list = [['石头', '剪刀'], ['剪刀', '布'], ['布', '石头']]prompt = """(0) 石头(1) 剪刀(2) 布请选择(0/1/2): """cwin = 0pwin = 0while cwin < 2 and pwin < 2: computer = random.choice(all_choices) ind = int(input(prompt)) player = all_choices[ind] print("Your choice: %s, Computer's choice: %s" % (player, computer)) if player == computer: print('\033[32;1m平局\033[0m') elif [player, computer] in win_list: pwin += 1 print('\033[31;1mYou WIN!!!\033[0m') else: cwin += 1 print('\033[31;1mYou LOSE!!!\033[0m') 29-文件对象基础操作
文件操作的三个步骤:打开、读写、关闭
# cp /etc/passwd /tmpf = open('/tmp/passwd') # 默认以r的方式打开纯文本文件data = f.read() # read()把所有内容读取出来print(data)data = f.read() # 随着读写的进行,文件指针向后移动。# 因为第一个f.read()已经把文件指针移动到结尾了,所以再读就没有数据了# 所以data是空字符串f.close()f = open('/tmp/passwd')data = f.read(4) # 读4字节f.readline() # 读到换行符\n结束f.readlines() # 把每一行数据读出来放到列表中f.close()################################f = open('/tmp/passwd')for line in f: print(line, end='')f.close()##############################f = open('图片地址', 'rb') # 打开非文本文件要加参数bf.read(4096)f.close()##################################f = open('/tmp/myfile', 'w') # 'w'打开文件,如果文件不存在则创建f.write('hello world!\n')f.flush() # 立即将缓存中的数据同步到磁盘f.writelines(['2nd line.\n', 'new line.\n'])f.close() # 关闭文件的时候,数据保存到磁盘##############################with open('/tmp/passwd') as f: print(f.readline())#########################f = open('/tmp/passwd')f.tell() # 查看文件指针的位置f.readline()f.tell()f.seek(0, 0) # 第一个数字是偏移量,第2位是数字是相对位置。 # 相对位置0表示开头,1表示当前,2表示结尾f.tell()f.close() 30-拷贝文件
拷贝文件就是以r的方式打开源文件,以w的方式打开目标文件,将源文件数据读出后,写到目标文件。
以下是【不推荐】的方式,但是可以工作:f1 = open('/bin/ls', 'rb')f2 = open('/root/ls', 'wb')data = f1.read()f2.write(data)f1.close()f2.close() 31-拷贝文件
每次读取4K,读完为止:
src_fname = '/bin/ls'dst_fname = '/root/ls'src_fobj = open(src_fname, 'rb')dst_fobj = open(dst_fname, 'wb')while True: data = src_fobj.read(4096) if not data: break dst_fobj.write(data)src_fobj.close()dst_fobj.close()
32-位置参数
注意:位置参数中的数字是字符形式的
import sysprint(sys.argv) # sys.argv是sys模块里的argv列表# python3 position_args.py# python3 position_args.py 10# python3 position_args.py 10 bob
33-函数应用-斐波那契数列
def gen_fib(l): fib = [0, 1] for i in range(l - len(fib)): fib.append(fib[-1] + fib[-2]) return fib # 返回列表,不返回变量fiba = gen_fib(10)print(a)print('-' * 50)n = int(input("length: "))print(gen_fib(n)) # 不会把变量n传入,是把n代表的值赋值给形参 34-函数-拷贝文件
import sysdef copy(src_fname, dst_fname): src_fobj = open(src_fname, 'rb') dst_fobj = open(dst_fname, 'wb') while True: data = src_fobj.read(4096) if not data: break dst_fobj.write(data) src_fobj.close() dst_fobj.close()copy(sys.argv[1], sys.argv[2])# 执行方式# cp_func.py /etc/hosts /tmp/zhuji.txt
35-函数-九九乘法表
def mtable(n): for i in range(1, n + 1): for j in range(1, i + 1): print('%s*%s=%s' % (j, i, i * j), end=' ') print()mtable(6)mtable(9) 36-模块基础
每一个以py作为扩展名的文件都是一个模块。
star.py:hi = 'hello world!'def pstar(n=50): print('*' * n)if __name__ == '__main__': pstar() pstar(30)在call_star.py中调用star模块:import starprint(star.hi)star.pstar()star.pstar(30) 37-生成密码/验证码
此文件名为:randpass.py
思路: 1、设置一个用于随机取出字符的基础字符串,本例使用大小写字母加数字 2、循环n次,每次随机取出一个字符 3、将各个字符拼接起来,保存到变量result中from random import choiceimport stringall_chs = string.ascii_letters + string.digits # 大小写字母加数字def gen_pass(n=8): result = '' for i in range(n): ch = choice(all_chs) result += ch return resultif __name__ == '__main__': print(gen_pass()) print(gen_pass(4)) print(gen_pass(10))
38-序列对象方法
from random import randintalist = list() # []list('hello') # ['h', 'e', 'l', 'l', 'o']list((10, 20, 30)) # [10, 20, 30] 元组转列表astr = str() # ''str(10) # '10'str(['h', 'e', 'l', 'l', 'o']) # 将列表转成字符串atuple = tuple() # ()tuple('hello') # ('h', 'e', 'l', 'l', 'o')num_list = [randint(1, 100) for i in range(10)]max(num_list)min(num_list) 39-序列对象方法2
alist = [10, 'john']# list(enumerate(alist)) # [(0, 10), (1, 'john')]# a, b = 0, 10 # a->0 ->10for ind in range(len(alist)): print('%s: %s' % (ind, alist[ind]))for item in enumerate(alist): print('%s: %s' % (item[0], item[1]))for ind, val in enumerate(alist): print('%s: %s' % (ind, val))atuple = (96, 97, 40, 75, 58, 34, 69, 29, 66, 90)sorted(atuple)sorted('hello')for i in reversed(atuple): print(i, end=',') 40-字符串方法
py_str = 'hello world!'py_str.capitalize()py_str.title()py_str.center(50)py_str.center(50, '#')py_str.ljust(50, '*')py_str.rjust(50, '*')py_str.count('l') # 统计l出现的次数py_str.count('lo')py_str.endswith('!') # 以!结尾吗?py_str.endswith('d!')py_str.startswith('a') # 以a开头吗?py_str.islower() # 字母都是小写的?其他字符不考虑py_str.isupper() # 字母都是大写的?其他字符不考虑'Hao123'.isdigit() # 所有字符都是数字吗?'Hao123'.isalnum() # 所有字符都是字母数字?' hello\t '.strip() # 去除两端空白字符,常用' hello\t '.lstrip()' hello\t '.rstrip()'how are you?'.split()'hello.tar.gz'.split('.')'.'.join(['hello', 'tar', 'gz'])'-'.join(['hello', 'tar', 'gz']) 41-字符串格式化
"%s is %s years old" % ('bob', 23) # 常用"%s is %d years old" % ('bob', 23) # 常用"%s is %d years old" % ('bob', 23.5) # %d是整数 常用"%s is %f years old" % ('bob', 23.5)"%s is %5.2f years old" % ('bob', 23.5) # %5.2f是宽度为5,2位小数"97 is %c" % 97"11 is %#o" % 11 # %#o表示有前缀的8进制"11 is %#x" % 11"%10s%5s" % ('name', 'age') # %10s表示总宽度为10,右对齐, 常用"%10s%5s" % ('bob', 25)"%10s%5s" % ('alice', 23)"%-10s%-5s" % ('name', 'age') # %-10s表示左对齐, 常用"%-10s%-5s" % ('bob', 25)"%10d" % 123"%010d" % 123"{} is {} years old".format('bob', 25)"{1} is {0} years old".format(25, 'bob')"{:<10}{:<8}".format('name', 'age') 42-shutil模块常用方法
import shutilwith open('/etc/passwd', 'rb') as sfobj: with open('/tmp/mima.txt', 'wb') as dfobj: shutil.copyfileobj(sfobj, dfobj) # 拷贝文件对象shutil.copyfile('/etc/passwd', '/tmp/mima2.txt')shutil.copy('/etc/shadow', '/tmp/') # cp /etc/shadow /tmp/shutil.copy2('/etc/shadow', '/tmp/') # cp -p /etc/shadow /tmp/shutil.move('/tmp/mima.txt', '/var/tmp/') # mv /tmp/mima.txt /var/tmp/shutil.copytree('/etc/security', '/tmp/anquan') # cp -r /etc/security /tmp/anquanshutil.rmtree('/tmp/anquan') # rm -rf /tmp/anquan# 将mima2.txt的权限设置成与/etc/shadow一样shutil.copymode('/etc/shadow', '/tmp/mima2.txt')# 将mima2.txt的元数据设置成与/etc/shadow一样# 元数据使用stat /etc/shadow查看shutil.copystat('/etc/shadow', '/tmp/mima2.txt')shutil.chown('/tmp/mima2.txt', user='zhangsan', group='zhangsan') 43-练习:生成文本文件
import osdef get_fname(): while True: fname = input('filename: ') if not os.path.exists(fname): break print('%s already exists. Try again' % fname) return fnamedef get_content(): content = [] print('输入数据,输入end结束') while True: line = input('> ') if line == 'end': break content.append(line) return contentdef wfile(fname, content): with open(fname, 'w') as fobj: fobj.writelines(content)if __name__ == '__main__': fname = get_fname() content = get_content() content = ['%s\n' % line for line in content] wfile(fname, content) 44-列表方法
alist = [1, 2, 3, 'bob', 'alice']alist[0] = 10alist[1:3] = [20, 30]alist[2:2] = [22, 24, 26, 28]alist.append(100)alist.remove(24) # 删除第一个24alist.index('bob') # 返回下标blist = alist.copy() # 相当于blist = alist[:]alist.insert(1, 15) # 向下标为1的位置插入数字15alist.pop() # 默认弹出最后一项alist.pop(2) # 弹出下标为2的项目alist.pop(alist.index('bob'))alist.sort()alist.reverse()alist.count(20) # 统计20在列表中出现的次数alist.clear() # 清空alist.append('new')alist.extend('new')alist.extend(['hello', 'world', 'hehe']) 45-检查合法标识符
import sysimport keywordimport stringfirst_chs = string.ascii_letters + '_'all_chs = first_chs + string.digitsdef check_id(idt): if keyword.iskeyword(idt): return "%s is keyword" % idt if idt[0] not in first_chs: return "1st invalid" for ind, ch in enumerate(idt[1:]): if ch not in all_chs: return "char in postion #%s invalid" % (ind + 2) return "%s is valid" % idtif __name__ == '__main__': print(check_id(sys.argv[1])) # python3 checkid.py abc@123
46-创建用户,设置随机密码
randpass模块参见《37-生成密码/验证码》
import subprocessimport sysfrom randpass import gen_passdef adduser(username, password, fname): data = """user information:%s: %s""" subprocess.call('useradd %s' % username, shell=True) subprocess.call( 'echo %s | passwd --stdin %s' % (password, username), shell=True ) with open(fname, 'a') as fobj: fobj.write(data % (username, password))if __name__ == '__main__': username = sys.argv[1] password = gen_pass() adduser(username, password, '/tmp/user.txt')# python3 adduser.py john 47-列表练习:模拟栈操作
stack = []def push_it(): item = input('item to push: ') stack.append(item)def pop_it(): if stack: print("from stack popped %s" % stack.pop())def view_it(): print(stack)def show_menu(): cmds = {'0': push_it, '1': pop_it, '2': view_it} # 将函数存入字典 prompt = """(0) push it(1) pop it(2) view it(3) exitPlease input your choice(0/1/2/3): """ while True: # input()得到字符串,用strip()去除两端空白,再取下标为0的字符 choice = input(prompt).strip()[0] if choice not in '0123': print('Invalid input. Try again.') continue if choice == '3': break cmds[choice]()if __name__ == '__main__': show_menu() 48-实现Linux系统中unix2dos功能
import sysdef unix2dos(fname): dst_fname = fname + '.txt' with open(fname) as src_fobj: with open(dst_fname, 'w') as dst_fobj: for line in src_fobj: line = line.rstrip() + '\r\n' dst_fobj.write(line) if __name__ == '__main__': unix2dos(sys.argv[1])
49-动画程序:@从一行#中穿过
\r是回车不换行
import timelength = 19count = 0while True: print('\r%s@%s' % ('#' * count, '#' * (length - count)), end='') try: time.sleep(0.3) except KeyboardInterrupt: print('\nBye-bye') break if count == length: count = 0 count += 1 50-字典基础用法
adict = dict() # {}dict(['ab', 'cd'])bdict = dict([('name', 'bob'),('age', 25)]){}.fromkeys(['zhangsan', 'lisi', 'wangwu'], 11)for key in bdict: print('%s: %s' % (key, bdict[key]))print("%(name)s: %(age)s" % bdict)bdict['name'] = 'tom'bdict['email'] = 'tom@tedu.cn'del bdict['email']bdict.pop('age')bdict.clear() 51-字典常用方法
adict = dict([('name', 'bob'),('age', 25)])len(adict)hash(10) # 判断给定的数据是不是不可变的,不可变数据才能作为keyadict.keys()adict.values()adict.items()# get方法常用,重要adict.get('name') # 取出字典中name对应的value,如果没有返回Noneprint(adict.get('qq')) # Noneprint(adict.get('qq', 'not found')) # 没有qq,返回指定内容print(adict.get('age', 'not found'))adict.update({'phone': '13455667788'}) 52-集合常用方法
# 集合相当于是无值的字典,所以也用{}表示myset = set('hello')len(myset)for ch in myset: print(ch)aset = set('abc')bset = set('cde')aset & bset # 交集aset.intersection(bset) # 交集aset | bset # 并集aset.union(bset) # 并集aset - bset # 差补aset.difference(bset) # 差补aset.add('new')aset.update(['aaa', 'bbb'])aset.remove('bbb')cset = set('abcde')dset = set('bcd')cset.issuperset(dset) # cset是dset的超集么?cset.issubset(dset) # cset是dset的子集么? 53-集合实例:取出第二个文件有,第一个文件没有的行
# cp /etc/passwd .# cp /etc/passwd mima# vim mima -> 修改,与passwd有些区别with open('passwd') as fobj: aset = set(fobj)with open('mima') as fobj: bset = set(fobj)with open('diff.txt', 'w') as fobj: fobj.writelines(bset - aset) 54-字典练习:模拟注册/登陆
import getpassuserdb = {}def register(): username = input('username: ') if username in userdb: print('%s already exists.' % username) else: password = input('password: ') userdb[username] = passworddef login(): username = input('username: ') password = getpass.getpass("password: ") if userdb.get(username) != password: print('login failed') else: print('login successful')def show_menu(): cmds = {'0': register, '1': login} prompt = """(0) register(1) login(2) exitPlease input your choice(0/1/2): """ while True: choice = input(prompt).strip()[0] if choice not in '012': print('Invalid inupt. Try again.') continue if choice == '2': break cmds[choice]()if __name__ == '__main__': show_menu() 55-计算千万次加法运算时间
import timeresult = 0start = time.time() # 返回运算前时间戳for i in range(10000000): result += iend = time.time() # 返回运算后时间戳print(result)print(end - start)
56-时间相关模块常用方法
import timet = time.localtime() # 返回当前时间的九元组time.gmtime() # 返回格林威治0时区当前时间的九元组time.time() # 常用,与1970-1-1 8:00之间的秒数,时间戳time.mktime(t) # 把九元组时间转成时间戳time.sleep(1)time.asctime() # 如果有参数,是九元组形式time.ctime() # 返回当前时间,参数是时间戳,常用time.strftime("%Y-%m-%d") # 常用time.strptime('2018-07-20', "%Y-%m-%d") # 返回九元组时间格式time.strftime('%H:%M:%S')###########################################from datetime import datetimefrom datetime import timedeltadatetime.today() # 返回当前时间的datetime对象datetime.now() # 同上,可以用时区作参数datetime.strptime('2018/06/30', '%Y/%m/%d') # 返回datetime对象dt = datetime.today()datetime.ctime(dt)datetime.strftime(dt, "%Y%m%d")days = timedelta(days=90, hours=3) # 常用dt2 = dt + daysdt2.yeardt2.monthdt2.daydt2.hour 57-os模块常用方法
import osos.getcwd() # 显示当前路径os.listdir() # ls -aos.listdir('/tmp') # ls -a /tmpos.mkdir('/tmp/mydemo') # mkdir /tmp/mydemoos.chdir('/tmp/mydemo') # cd /tmp/mydemoos.listdir()os.mknod('test.txt') # touch test.txtos.symlink('/etc/hosts', 'zhuji') # ln -s /etc/hosts zhujios.path.isfile('test.txt') # 判断test.txt是不是文件os.path.islink('zhuji') # 判断zhuji是不是软链接os.path.isdir('/etc')os.path.exists('/tmp') # 判断是否存在os.path.basename('/tmp/abc/aaa.txt')os.path.dirname('/tmp/abc/aaa.txt')os.path.split('/tmp/abc/aaa.txt')os.path.join('/home/tom', 'xyz.txt')os.path.abspath('test.txt') # 返回当前目录test.txt的绝对路径 58-pickle存储器
import pickle"""以前的文件写入,只能写入字符串,如果希望把任意数据对象(数字、列表等)写入文件,取出来的时候数据类型不变,就用到pickle了"""# shop_list = ["eggs", "apple", "peach"]# with open('/tmp/shop.data', 'wb') as fobj:# pickle.dump(shop_list, fobj)with open('/tmp/shop.data', 'rb') as fobj: mylist = pickle.load(fobj)print(mylist[0], mylist[1], mylist[2]) 59-异常处理基础
try: # 把有可能发生异常的语句放到try里执行 n = int(input("number: ")) result = 100 / n print(result)except ValueError: print('invalid number')except ZeroDivisionError: print('0 not allowed')except KeyboardInterrupt: print('Bye-bye')except EOFError: print('Bye-bye')print('Done') 60-异常处理完整语法
try: n = int(input("number: ")) result = 100 / nexcept (ValueError, ZeroDivisionError): print('invalid number')except (KeyboardInterrupt, EOFError): print('\nBye-bye')else: print(result) # 异常不发生时才执行else子句finally: print('Done') # 不管异常是否发生都必须执行的语句# 常用形式有try-except和try-finally 61-自定义异常
def set_age(name, age): if not 0 < age < 120: raise ValueError('年龄超过范围') # 自主决定触发什么样的异常 print("%s is %d years old" % (name, age))def set_age2(name, age): assert 0 < age < 120, '年龄超过范围' # 断言异常 print("%s is %d years old" % (name, age))if __name__ == '__main__': set_age('zhangsan', 20) set_age2('lisi', 200) 62-变量作用域
x = 10 # 全局变量从定义开始到程序结束,一直可见可用def foo(): print(x)foo()def bar(): x = 20 # 此处的x是局部变量,将全局变量遮盖住,不会影响全局变量的值 print(x)bar() # x -> 20print(x) # x -> 10def aaa(): global x # 在局部引用全局变量 x = 100 # 将全局变量x重新赋值为100 print(x) # x -> 100aaa()print(x) # x -> 100
63-函数调用:参数使用注意事项
def get_age(name, age): print('%s is %s years old' % (name, age))get_age('bob', 25) # 参数按顺序传递get_age(25, 'bob') # 没有语法错误,但是语义不对get_age(age=25, name='bob')# get_age() # Error,少参数# get_age('bob', 25, 100) # Error,多参数# get_age(age=25, 'bob') # 语法错误# get_age(25, name='bob') # 错误,参数按顺序传递,name得到多个值get_age('bob', age=25) 64-参数个数不固定的函数
def func1(*args): # *表示args是个元组 print(args)def func2(**kwargs): # **表示kwargs是个字典 print(kwargs)def func3(x, y): print(x * y)def func4(name, age): print("%s is %s years old" % (name, age))if __name__ == '__main__': func1() func1(10) func1(10, 'bob') func2() func2(name='bob', age=25) func3(*[10, 5]) # 调用的时候,*表示拆开后面的数据类型 func4(**{'name': 'bob', 'age': 25}) # name='bob', age=25 65-偏函数基础应用
偏函数可以理解为,将现有函数的某些参数固定下来,构造成一个新函数。新函数调用就不用写那么多参数了
from functools import partialdef foo(a, b, c, d, f): return a + b + c + d + fif __name__ == '__main__': print(foo(10, 20, 30, 40, 5)) print(foo(10, 20, 30, 40, 25)) print(foo(10, 20, 30, 40, 69)) print(foo(10, 20, 30, 40, 32)) add = partial(foo, a=10, b=20, c=30, d=40) print(add(f=5)) # foo(10, 20, 30, 40, 5) print(add(f=8)) # foo(10, 20, 30, 40, 8)
66-偏函数应用:简单的图形窗口
import tkinterfrom functools import partialroot = tkinter.Tk()lb = tkinter.Label(text="Hello world!")b1 = tkinter.Button(root, fg='white', bg='blue', text='Button 1') # 不使用偏函数生成按钮MyBtn = partial(tkinter.Button, root, fg='white', bg='blue') # 使用偏函数定义MyBtnb2 = MyBtn(text='Button 2') b3 = MyBtn(text='quit', command=root.quit)lb.pack()b1.pack()b2.pack()b3.pack()root.mainloop()
67-生成器基础
生成器也是函数,只是常规函数通过return返回一个值,而生成器可以通过yield返回很多中间结果
def mygen(): yield 'hello' a = 10 + 20 yield a yield [1, 2, 3]if __name__ == '__main__': m = mygen() for i in m: print(i) for i in m: print(i) # 无值,因为生成器对象只能用一次
68-生成器实例:每次取出文件的10行内容
def blocks(fobj): block = [] counter = 0 for line in fobj: block.append(line) counter += 1 if counter == 10: yield block # 返回中间结果,下次取值,从这里继续向下执行 block = [] counter = 0 if block: # 文件最后不够10行的部分 yield blockif __name__ == '__main__': fobj = open('/tmp/passwd') # cp /etc/passwd /tmp for lines in blocks(fobj): print(lines) print() fobj.close() 69-匿名函数和filter
from random import randintdef func1(x): return x % 2if __name__ == '__main__': alist = [randint(1, 100) for i in range(10)] print(alist) # filter要求第一个参数是函数,该函数必须返回True或False # 执行时把alist的每一项作为 func1的参数,返回真留下,否则过滤掉 # filter函数的参数又是函数,称作高阶函数 result = filter(func1, alist) # 不使用匿名函数 print(list(result)) result2 = filter(lambda x: x % 2, alist) # 匿名函数,不使用常规函数 print(list(result2))
70-匿名函数和map
from random import randintdef func(x): return x * 2 + 1if __name__ == '__main__': alist = [randint(1, 100) for i in range(10)] print(alist) # map将第二个参数中的每一项交给func函数进行加工,保留加工后的结果 result = map(func, alist) # 使用常规则函数作为参数 result2 = map(lambda x: x * 2 + 1, alist) # 使用匿名函数作为参数 print(list(result)) print(list(result2))
71-函数练习:数学游戏
随机生成100以内的两个数字,实现随机的加减法。如果是减法,结果不能是负数。
算错三次,给出正确答案lt = cmds[op](*nums) prompt = "%s %s %s = " % (nums[0], op, nums[1]) tries = 0 while tries < 3: try: answer = int(input(prompt)) except: # 简单粗暴地捕获所有异常 continue if answer == result: print('Very good!') break else: print('Wrong answer.') tries += 1 else: # 此得是while的else,全算错才给答案,算对了就不用给出答案了 print('%s%s' % (prompt, result))if __name__ == '__main__': while True: exam() try: yn = input("Continue(y/n)? ").strip()[0] except IndexError: continue except (KeyboardInterrupt, EOFError): print() yn = 'n' if yn in 'nN': break 72-数学游戏进阶
与前面例子《71-函数练习:数学游戏》相同,只是加减法函数更换为匿名函数
from random import randint, choicedef exam(): cmds = {'+': lambda x, y: x + y, '-': lambda x, y: x - y} nums = [randint(1, 100) for i in range(2)] nums.sort(reverse=True) op = choice('+-') result = cmds[op](*nums) prompt = "%s %s %s = " % (nums[0], op, nums[1]) tries = 0 while tries < 3: try: answer = int(input(prompt)) except: continue if answer == result: print('Very good!') break else: print('Wrong answer.') tries += 1 else: print('%s%s' % (prompt, result))if __name__ == '__main__': while True: exam() try: yn = input("Continue(y/n)? ").strip()[0] except IndexError: continue except (KeyboardInterrupt, EOFError): print() yn = 'n' if yn in 'nN': break 73-递归函数计算阶乘
递归函数就是在函数内部继续调用自己
def func(n): # 5 if n == 1: return n return n * func(n - 1) # 5 * func(4) # 5 * 4 * func(3) # 5 * 4 * 3 * func(2) # 5 * 4 * 3 * 2 * func(1) # 5 * 4 * 3 * 2 * 1if __name__ == '__main__': print(func(5)) print(func(6))
74-递归函数练习:逐级列出目录内容
listdir.py:import osimport sysdef list_files(path): if os.path.isdir(path): print(path + ':') content = os.listdir(path) print(content) for fname in content: fname = os.path.join(path, fname) list_files(fname)if __name__ == '__main__': list_files(sys.argv[1]) # python3 listdir.py /etc
75-递归函数练习:快速排序
思路:
1、假设列表中第一个数是中间值,比它小的数字放到smaller列表中,比它的大的数字放到larger列表中。再将这三项拼接起来 2、因为smaller和larger仍然是无序列表,需要使用相同的方法继续分割 3、如果列表的长度是0或1,那么就没有必要再排序了from random import randintdef quick_sort(num_list): if len(num_list) < 2: return num_list middle = num_list[0] smaller = [] larger = [] for i in num_list[1:]: if i < middle: smaller.append(i) else: larger.append(i) return quick_sort(smaller) + [middle] + quick_sort(larger)if __name__ == '__main__': alist = [randint(1, 100) for i in range(10)] print(alist) print(quick_sort(alist))
76-闭包的用法
下面的代码用到了《66-偏函数应用:简单的图形窗口》
图形窗口上的按钮有个command选项,其实它就是一个函数。如下:import tkinterfrom functools import partialdef hello(): lb.config(text="Hello China!")def welcome(): lb.config(text="Hello Tedu!")root = tkinter.Tk()lb = tkinter.Label(text="Hello world!", font="Times 26")MyBtn = partial(tkinter.Button, root, fg='white', bg='blue')b1 = MyBtn(text='Button 1', command=hello)b2 = MyBtn(text='Button 2', command=welcome)b3 = MyBtn(text='quit', command=root.quit)lb.pack()b1.pack()b2.pack()b3.pack()root.mainloop()按下Button 1和Button 2就会执行hello和welcome两个函数。这两个函数非常类似,如果有10个按钮,并且都是类似的呢?换成内部函数、闭包的的语法如下:from functools import partialdef hello(word): def welcome(): lb.config(text="Hello %s!" % word) return welcome # hello函数的返回值还是函数root = tkinter.Tk()lb = tkinter.Label(text="Hello world!", font="Times 26")MyBtn = partial(tkinter.Button, root, fg='white', bg='blue')b1 = MyBtn(text='Button 1', command=hello('China'))b2 = MyBtn(text='Button 2', command=hello('Tedu'))b3 = MyBtn(text='quit', command=root.quit)lb.pack()b1.pack()b2.pack()b3.pack()root.mainloop() 77-装饰器基础
def color(func): def red(): return '\033[31;1m%s\033[0m' % func() return reddef hello(): return 'Hello World!'@colordef welcome(): return 'Hello China!'if __name__ == '__main__': hello = color(hello) # 此种写法可以换成为welcome加上@color的写法 print(hello()) print(welcome()) # welcome因为有装饰器,所以调用时不是调用welcome函数 # 而是相当于color(welcome)() # color(welcome)返回red,color(welcome)() # 等价于red()
78-带有参数的装饰器
def color(func): def red(*args): return '\033[31;1m%s\033[0m' % func(*args) return red@colordef hello(word): return 'Hello %s!' % word@colordef welcome(): return 'How are you?'if __name__ == '__main__': print(hello('China')) print(welcome()) 79-装饰器,返回不同颜色的字体
def colors(c): def set_color(func): def red(*word): return '\033[31;1m%s\033[0m' % func(*word) def green(*word): return '\033[32;1m%s\033[0m' % func(*word) adict = {'red': red, 'green': green} return adict[c] return set_color@colors('red')def hello(): return 'Hello world!'@colors('green')def welcome(word): return 'Hello %s' % wordif __name__ == '__main__': print(hello()) # -> hello = set_color(hello) print(welcome('China')) 80-综合练习:记账小程序
1、记账时手头有一万块钱
2、可以记录花的钱、存的钱,以及收支明细balance = pickle.load(fobj) - amount with open(wallet, 'wb') as fobj: pickle.dump(balance, fobj) with open(record, 'a') as fobj: fobj.write( '%-12s%-8s%-8s%-10s%-20s\n' % (date, amount, '', balance, comment) )def save(wallet, record): # 记录存钱的函数 amount = int(input('amount: ')) comment = input('comment: ') date = time.strftime('%Y-%m-%d') with open(wallet, 'rb') as fobj: balance = pickle.load(fobj) + amount with open(wallet, 'wb') as fobj: pickle.dump(balance, fobj) with open(record, 'a') as fobj: fobj.write( '%-12s%-8s%-8s%-10s%-20s\n' % (date, '', amount, balance, comment) )def query(wallet, record): # 查询收支明细的函数 print('%-12s%-8s%-8s%-10s%-20s' % ('date', 'cost', 'save', 'balace', 'comment')) with open(record) as fobj: for line in fobj: print(line, end='') with open(wallet, 'rb') as fobj: balance = pickle.load(fobj) print("Latest Balance: %d" % balance)def show_menu(): cmds = {'0': cost, '1': save, '2': query} prompt = """(0) cost(1) save(2) query(3) exitPlease input your choice(0/1/2/3): """ wallet = 'wallet.data' record = 'record.txt' if not os.path.exists(wallet): with open(wallet, 'wb') as fobj: pickle.dump(10000, fobj) while True: try: choice = input(prompt).strip()[0] except IndexError: continue except (KeyboardInterrupt, EOFError): print() choice = '3' if choice not in '0123': print('Invalid input. Try again.') continue if choice == '3': break cmds[choice](wallet, record)if __name__ == '__main__': show_menu() 81-hashlib模块之计算md5值
check_md5.pyimport hashlibimport sysdef check_md5(fname): m = hashlib.md5() with open(fname, 'rb') as fobj: while True: data = fobj.read(4096) if not data: break m.update(data) return m.hexdigest()if __name__ == '__main__': print(check_md5(sys.argv[1])) # python3 check_md5.py /etc/passwd
82-tarfile模块的基础应用
import tarfile# 压缩文件的方法 tar = tarfile.open('/tmp/demo.tar.gz', 'w:gz') # gzip压缩 tar.add('/etc/hosts') tar.add('/etc/security') tar.close() # tar tvzf /tmp/demo.tar.gz # 解压文件的方法 tar = tarfile.open('/tmp/demo.tar.gz', 'r:gz') tar.extractall() # 解压所有文件到当前目录 tar.close() 83-OOP基础
为玩具厂创建一个玩具熊类
玩具熊有名字、尺寸、颜色这些数据属性;还有唱歌、说话的行为class BearToy: def __init__(self, nm, color, size): """__init__在实例化时自动执行,实例本身自动作为第一个参数传递给self self只是习惯用的名字,不是必须使用 """ self.name = nm self.color = color # 绑定属性到实例 self.size = size def sing(self): print('lalala...') def speak(self): print('My name is %s' % self.name)if __name__ == '__main__': tidy = BearToy('Tidy', 'White', 'Large') # 调用__init__ print(tidy.color) print(tidy.size) tidy.sing() tidy.speak() 84-OOP之组合
如果两个类有本质不同,其中一类的对象是另一个类对象的组件时,使用组合是最佳方案。
玩具熊还有生产厂商的信息,生产厂商的信息可以作为玩具熊的一个属性class Vendor: def __init__(self, phone, email): self.phone = phone self.email = email def call(self): print('calling %s' % self.phone)class BearToy: def __init__(self, color, size, phone, email): self.color = color # 绑定属性到实例 self.size = size self.vendor = Vendor(phone, email)if __name__ == '__main__': bigbear = BearToy('Brown', 'Middle', '400-111-8989', 'sales@tedu.cn') print(bigbear.color) bigbear.vendor.call() 85-OOP之继承
如果两个类有很多相同之处,使用继承更为合理
新品玩具熊增加了一个跑的行为,其他与原来的玩具熊一致class BearToy: def __init__(self, nm, color, size): self.name = nm self.color = color # 绑定属性到实例 self.size = size def sing(self): print('lalala...') def speak(self): print('My name is %s' % self.name)class NewBear(BearToy): def run(self): print('running...')if __name__ == '__main__': b1 = NewBear('venie', 'Brown', 'Small') b1.sing() b1.run() 86-OOP之子类调用父类方法
如果子类和父类具有同名的方法,那么父类方法将被遮盖住
可以在子类中明确指明调用的是父类方法,而不是子类的同名方法class BearToy: def __init__(self, nm, color, size): self.name = nm self.color = color # 绑定属性到实例 self.size = size def sing(self): print('lalala...') def speak(self): print('My name is %s' % self.name)class NewBear(BearToy): def __init__(self, nm, color, size, date): # BearToy.__init__(self, nm, color, size) # 以下写法完全一样,更推荐下面写法 super(NewBear, self).__init__(nm, color, size) self.date = date # 新品玩具熊增加玩具熊的生产日期 def run(self): print('running...')if __name__ == '__main__': b1 = NewBear('venie', 'Brown', 'Small', '2018-07-20') b1.sing() b1.run() 87-OOP之必需掌握的magic
class Book: def __init__(self, title, author, pages): self.title = title self.author = author self.pages = pages def __str__(self): return '《%s》' % self.title def __call__(self): print('《%s》is written by %s' % (self.title, self.author))if __name__ == '__main__': py_book = Book('Core Python', 'Wesley', 800) # 调用__init__()方法 print(py_book) # 调用__str__ py_book() # 调用__call__ 88-OOP之多重继承
类的父类(基类)可以有很多个,子类可以调用所有父类的方法
如果有重名方法,生效的顺序是自下而上,自左而右。当然最好不要出现重名方法bar(self): print('in B bar') def hello(self): print('B hello')class C(B, A): pass # def hello(self): # print('C hello')if __name__ == '__main__': c = C() c.foo() c.bar() c.hello() 89-OOP之类方法和静态方法
通过Date创建实例,也可以通过Date.create创建实例
class Date: def __init__(self, year, month, date): self.year = year self.month = month self.date = date @classmethod # 类方法,不用创建实例即可调用 def create(cls, dstr): # cls表示类本身, class的缩写 y, m, d = map(int, dstr.split('-')) # map(int, ['2000', '5', '4']) dt = cls(y, m, d) # 即Date(y, m, d) return dt @staticmethod # 静态方法,写在类的外面,可以独立成为一个函数,“愣”把它放到类中了 def is_date_valid(dstr): y, m, d = map(int, dstr.split('-')) return 1 <= d <= 31 and 1 <= m <=12 and y < 4000if __name__ == '__main__': bith_date = Date(1995, 12, 3) print(Date.is_date_valid('2000-5-4')) day = Date.create('2000-5-4') print(day) 90-综合练习:备份程序
1、既要可以实现完全备份,又要实现增量备份
2、完全备份时,将目录打个tar包,计算每个文件的md5值 3、增量备份时,备份有变化的文件和新增加的文件,更新md5值import timeimport osimport tarfileimport hashlibimport pickledef check_md5(fname): m = hashlib.md5() with open(fname, 'rb') as fobj: while True: data = fobj.read(4096) if not data: break m.update(data) return m.hexdigest()def full_backup(src_dir, dst_dir, md5file): fname = os.path.basename(src_dir.rstrip('/')) fname = '%s_full_%s.tar.gz' % (fname, time.strftime('%Y%m%d')) fname = os.path.join(dst_dir, fname) md5dict = {} tar = tarfile.open(fname, 'w:gz') tar.add(src_dir) tar.close() for path, folders, files in os.walk(src_dir): for each_file in files: key = os.path.join(path, each_file) md5dict[key] = check_md5(key) with open(md5file, 'wb') as fobj: pickle.dump(md5dict, fobj)def incr_backup(src_dir, dst_dir, md5file): fname = os.path.basename(src_dir.rstrip('/')) fname = '%s_incr_%s.tar.gz' % (fname, time.strftime('%Y%m%d')) fname = os.path.join(dst_dir, fname) md5dict = {} with open(md5file, 'rb') as fobj: oldmd5 = pickle.load(fobj) for path, folders, files in os.walk(src_dir): for each_file in files: key = os.path.join(path, each_file) md5dict[key] = check_md5(key) with open(md5file, 'wb') as fobj: pickle.dump(md5dict, fobj) tar = tarfile.open(fname, 'w:gz') for key in md5dict: if oldmd5.get(key) != md5dict[key]: tar.add(key) tar.close()if __name__ == '__main__': # mkdir /tmp/demo; cp -r /etc/security /tmp/demo src_dir = '/tmp/demo/security' dst_dir = '/var/tmp/backup' # mkdir /var/tmp/backup md5file = '/var/tmp/backup/md5.data' if time.strftime('%a') == 'Mon': full_backup(src_dir, dst_dir, md5file) else: incr_backup(src_dir, dst_dir, md5file) 91-OOP练习:实现unix2dos和dos2unix功能
windows文本行结束标志是\r\n,非windows的是\n
import osclass Convert: def __init__(self, fname): self.fname = fname def to_linux(self): dst_fname = os.path.splitext(self.fname)[0] + '.linux' with open(self.fname, 'r') as src_fobj: with open(dst_fname, 'w') as dst_fobj: for line in src_fobj: line = line.rstrip() + '\n' dst_fobj.write(line) def to_windows(self): dst_fname = os.path.splitext(self.fname)[0] + '.windows' with open(self.fname, 'r') as src_fobj: with open(dst_fname, 'w') as dst_fobj: for line in src_fobj: line = line.rstrip() + '\r\n' dst_fobj.write(line)if __name__ == '__main__': c = Convert('/tmp/passwd') # cp /etc/passwd /tmp c.to_linux() c.to_windows() 92-re模块基础用法
import rem = re.match('f..', 'food') # 匹配到返回对象print(re.match('f..', 'seafood')) # 匹配不到返回Nonem.group() # 返回匹配的值m = re.search('f..', 'seafood')m.group()re.findall('f..', 'seafood is food') # 返回所有匹配项组成的列表result = re.finditer('f..', 'seafood is food') # 返回匹配对象组成的迭代器for m in result: # 从迭代器中逐个取出匹配对象 print(m.group())re.sub('f..', 'abc', 'fish is food')re.split('\.|-', 'hello-world.tar.gz') # 用.和-做切割符号patt = re.compile('f..') # 先把要匹配的模式编译,提升效率m = patt.search('seafood') # 指定在哪个字符串中匹配m.group() 93-re练习:匹配文件中指定模式
import redef count_patt(fname, patt): cpatt = re.compile(patt) result = {} with open(fname) as fobj: for line in fobj: m = cpatt.search(line) # 如果匹配不到,返回None if m: key = m.group() result[key] = result.get(key, 0) + 1 return resultif __name__ == '__main__': fname = 'access_log' # apache日志文件 ip = '^(\d+\.){3}\d+' # 日志开头的ip地址 print(count_patt(fname, ip)) br = 'Firefox|MSIE|Chrome' # 日志中客户端浏览器 print(count_patt(fname, br)) 94-re练习:模式匹配进阶写法
import refrom collections import Counter # Counter对象是有序的,字典无序class CountPatt: def __init__(self, fname): self.fname = fname def count_patt(self, patt): cpatt = re.compile(patt) result = Counter() with open(self.fname) as fobj: for line in fobj: m = cpatt.search(line) # 如果匹配不到,返回None if m: result.update([m.group()]) return resultif __name__ == '__main__': c = CountPatt('access_log') ip = '^(\d+\.){3}\d+' br = 'Firefox|MSIE|Chrome' a = c.count_patt(ip) print(a) print(a.most_common(3)) # 访问量最大的前三名 print(c.count_patt(br)) 95-socket基础:TCP服务器流程
服务器启动后,测试可以使用:telnet 127.0.0.1 12345
import sockethost = '' # 表示本机所有地址 0.0.0.0port = 12345 # 应该大于1024addr = (host, port)s = socket.socket() # 默认值就是基于TCP的网络套接字# 设置选项,程序结束之后可以立即再运行,否则要等60秒s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)s.bind(addr) # 绑定地址到套接字s.listen(1) # 启动侦听进程cli_sock, cli_addr = s.accept() # 等待客户端连接print('Client connect from:', cli_addr)print(cli_sock.recv(1024)) # 一次最多读1024字节数据cli_sock.send(b'I 4 C U\r\n') # 发送的数据要求是bytes类型cli_sock.close()s.close() 96-可重用的TCP服务器
在95-socket基础:TCP服务器流程中,TCP服务器只能一个客户端连接,客户端也只能发送一条消息。本例允许客户端发送多条消息,输入end结束。客户端退出后,服务器程序不再退出,可以为下一个客户端提供服务:
import sockethost = ''port = 12345addr = (host, port)s = socket.socket()s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)s.bind(addr)s.listen(1)while True: cli_sock, cli_addr = s.accept() print('Client connect from:', cli_addr) while True: data = cli_sock.recv(1024) if data.strip() == b'end': break print(data.decode('utf8')) # bytes类型转为string类型 data = input('> ') + '\r\n' # 获得的是string类型 cli_sock.send(data.encode('utf8')) # 转成bytes类型发送 cli_sock.close()s.close() 97-简单而完整的TCP服务器
客户端可以通过telnet 127.0.0.1 12345来访问
每发送一段文字,将会收到加上当前时间的文字import socketfrom time import strftimeclass TcpTimeServer: def __init__(self, host='', port=12345): self.addr = (host, port) self.serv = socket.socket() self.serv.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) self.serv.bind(self.addr) self.serv.listen(1) def chat(self, c_sock): while True: data = c_sock.recv(1024) if data.strip() == b'quit': break data = '[%s] %s' % (strftime('%H:%M:%S'), data.decode('utf8')) c_sock.send(data.encode('utf8')) c_sock.close() def mainloop(self): while True: cli_sock, cli_addr = self.serv.accept() self.chat(cli_sock) self.serv.close()if __name__ == '__main__': s = TcpTimeServer() s.mainloop() 98-简单的TCP客户端
客户端连接服务器的12345端口,在单独的一行输入end结束客户端程序
import sockethost = '192.168.4.254' # 服务器IP地址port = 12345 # 服务器端口addr = (host, port)c = socket.socket()c.connect(addr)while True: data = input('> ') + '\r\n' c.send(data.encode('utf8')) # 服务器收到end结束,所以要先发送再判断 if data.strip() == 'end': break data = c.recv(1024) print(data.decode('utf8'))c.close() 99-简单的UDP服务器流程
UDP是非面向连接的,不用listen、不用accept
UDP不区分客户端,就算是同一客户端发来的多个数据包,udp服务器也不区分,与处理多个客户端发来的数据包等同对待import socketfrom time import strftimehost = ''port = 12345addr = (host, port)s = socket.socket(type=socket.SOCK_DGRAM)s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)s.bind(addr)while True: data, cli_addr = s.recvfrom(1024) clock = strftime('%H:%M:%S') data = data.decode('utf8') data = '[%s] %s' % (clock, data) s.sendto(data.encode('utf8'), cli_addr)s.close() 100-简单的UDP客户端流程
UDP客户端非常简单,只要把数据发送到服务器地址就可以了
import sockethost = '192.168.4.254'port = 12345addr = (host, port)c = socket.socket(type=socket.SOCK_DGRAM)while True: data = input('> ') if data.strip() == 'quit': break c.sendto(data.encode('utf8'), addr) print(c.recvfrom(1024)[0].decode('utf8')) # print(c.recvfrom(1024))c.close() 101-多进程基础
fork()后会出现子进程,父子进程都打印Hello World!,所以会有两行相同的内容输出。
import osprint('starting...')os.fork() # 生成子进程,后续代码同时在父子进程中执行print('Hello World!') 可以根据fork()返回值判断是父进程,还是子进程
import osprint('starting...')pid = os.fork() # 返回值是个数字,对于父进程,返回值是子进程PID,子进程是0if pid: print('In parent') # 父进程执行的代码else: print('In child') # 子进程执行的代码print('Done') # 父子进程都会执行的代码 多进程编程时,要明确父子进程的工作。如:父进程只用于fork子进程;子进程做具体的工作,如果在循环结构中,做完后要退出,否则子进程还会再产生子进程、孙进程……子子孙孙无穷匮也,系统崩溃。
import osfor i in range(5): pid = os.fork() # 父进程的工作是生成子进程 if not pid: # 如果是子进程,工作完后,结束,不要进入循环 print('hello') exit() # 注释这一行执行,查看结果,分析原因 102-多进程的ping
没有多进程,ping一个网段的IP地址往往要花费几十分钟;使用多进程,几秒钟解决。
import subprocessimport osdef ping(host): rc = subprocess.call( 'ping -c2 %s &> /dev/null' % host, shell=True ) if rc: print('%s: down' % host) else: print('%s: up' % host)if __name__ == '__main__': ips = ('192.168.1.%s' % i for i in range(1, 255)) for ip in ips: pid = os.fork() if not pid: ping(ip) exit() 103-多进程的效率
没有多进程,即使CPU有多个核心,程序只是运行在一个核心上,无法利用多进程提升效率。5000万次加法,如果需要2.5秒,调用两次共花费5秒。
import timedef calc(): result = 0 for i in range(1, 50000001): result += i print(result)if __name__ == '__main__': start = time.time() calc() calc() end = time.time() print(end - start)
通过多进程,程序运行在多个核心上,同样的调用两次5000万次加法运算,时间仅为一半。
import timeimport osdef calc(): result = 0 for i in range(1, 50000001): result += i print(result)if __name__ == '__main__': start = time.time() for i in range(2): pid = os.fork() if not pid: calc() exit() os.waitpid(-1, 0) # 挂起父进程,直到子进程结束才继续向下执行 os.waitpid(-1, 0) # 每个waitpid只能处理一个僵尸进程,两个子进程需要调用两次 end = time.time() print(end - start)
104-僵尸进程
多进程编程要注意僵尸进程。子进程没有可执行代码后将变成僵尸进程,如果父进程一直运行,又没有处理僵尸进程的代码,僵尸进程也将一直存在,消耗资源。僵尸进程无法通过kill命令杀掉。
import osimport timepid = os.fork()if pid: print('In parent. sleeping...') time.sleep(60) print('parent done.')else: print('in child. sleeping...') time.sleep(10) print('child done') # 10秒后,子进程变成了僵尸进程# watch -n1 ps a 当子进程成为僵尸进程时,显示为Z# kill 试图杀死僵尸进程、父进进程,查看结果 105-解决僵尸进程问题
os.waitpid()的第2个参数,0表示挂起父进程,1表示不挂起父进程。import osimport timepid = os.fork()if pid: print('In parent. sleeping...') print(os.waitpid(-1, 1)) # 无僵尸进程可以处理,返回0 time.sleep(20) print(os.waitpid(-1, 1)) # 处理僵尸进程,返回子进程PIP time.sleep(60) print('parent done.')else: print('in child. sleeping...') time.sleep(10) print('child done')# watch -n1 ps a 当子进程成为僵尸进程时,显示为Z# kill 试图杀死僵尸进程、父进进程,查看结果 106-基于多进程的时间消息服务器
1、支持多客户端同时访问
2、客户端向服务器发送消息后,服务器把消息加上时间发回客户端 3、每个客户端断开后会产生僵尸进程,新客户端连接时销毁所有的僵尸进程import socketimport osfrom time import strftimeclass TcpTimeServer: def __init__(self, host='', port=12345): self.addr = (host, port) self.serv = socket.socket() self.serv.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) self.serv.bind(self.addr) self.serv.listen(1) def chat(self, c_sock): while True: data = c_sock.recv(1024) if data.strip() == b'quit': break data = '[%s] %s' % (strftime('%H:%M:%S'), data.decode('utf8')) c_sock.send(data.encode('utf8')) c_sock.close() def mainloop(self): while True: cli_sock, cli_addr = self.serv.accept() pid = os.fork() if pid: cli_sock.close() while True: result = os.waitpid(-1, 1)[0] # waitpid会优先处理僵尸进程 if result == 0: break else: self.serv.close() self.chat(cli_sock) exit() self.serv.close()if __name__ == '__main__': s = TcpTimeServer() s.mainloop() 107-基于多线程的ping
多线程与多进程类似,但是每个线程没有自己的资源空间,它们共用进程的资源。
多线程没有僵尸进程的问题。import subprocessimport threadingdef ping(host): rc = subprocess.call( 'ping -c2 %s &> /dev/null' % host, shell=True ) if rc: print('%s: down' % host) else: print('%s: up' % host)if __name__ == '__main__': ips = ['172.40.58.%s' % i for i in range(1, 255)] for ip in ips: # 创建线程,ping是上面定义的函数, args是传给ping函数的参数 t = threading.Thread(target=ping, args=(ip,)) t.start() # 执行ping(ip) 108-多线程的效率
python的多线程有一个GIL(全局解释器锁),使得多个线程,某一时刻只有一个线程发送给CPU处理。所以多线程不适用计算密集型应用,更适合IO密集型应用。
以下两次计算5000万次加法运算和不用多线程相比,没有效率的提升。因为CPU有上下文切换,甚至可能多线程更慢。import timeimport threadingdef calc(): result = 0 for i in range(1, 50000001): result += i print(result)if __name__ == '__main__': start = time.time() t1 = threading.Thread(target=calc) t1.start() t2 = threading.Thread(target=calc) t2.start() t1.join() # 挂起主进程,当t1线程执行完后才继续向下执行 t2.join() end = time.time() print(end - start)
109-基于多线程的时间消息服务器
与106-基于多进程的时间消息服务器类似,只是换成了多线程。
import socketimport threadingfrom time import strftimeclass TcpTimeServer: def __init__(self, host='', port=12345): self.addr = (host, port) self.serv = socket.socket() self.serv.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) self.serv.bind(self.addr) self.serv.listen(1) def chat(self, c_sock): while True: data = c_sock.recv(1024) if data.strip() == b'quit': break data = '[%s] %s' % (strftime('%H:%M:%S'), data.decode('utf8')) c_sock.send(data.encode('utf8')) c_sock.close() def mainloop(self): while True: cli_sock, cli_addr = self.serv.accept() t = threading.Thread(target=self.chat, args=(cli_sock,)) t.start() self.serv.close()if __name__ == '__main__': s = TcpTimeServer() s.mainloop() 110-并行批量管理远程服务器
脚本名为remote_comm.py,执行方式如下:
python3 remote_comm.py 服务器IP地址文件 "在远程服务器上要执行的命令"
如:
# python3 remote_comm.py serverips.txt "useradd zhangsan"
远程服务器的密码以交互方式获得
import threadingimport osdef remote_comm(host, pwd, command): ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect(hostname=host, username='root', password=pwd) stdin, stdout, stderr = ssh.exec_command(command) out = stdout.read() error = stderr.read() if out: print('[%s] OUT:\n%s' % (host, out.decode('utf8'))) if error: print('[%s] ERROR:\n%s' % (host, error.decode('utf8'))) ssh.close()if __name__ == '__main__': if len(sys.argv) != 3: print('Usage: %s ipaddr_file "command"' % sys.argv[0]) exit(1) if not os.path.isfile(sys.argv[1]): print('No such file:', sys.argv[1]) exit(2) fname = sys.argv[1] command = sys.argv[2] pwd = getpass.getpass() with open(fname) as fobj: ips = [line.strip() for line in fobj] for ip in ips: t = threading.Thread(target=remote_comm, args=(ip, pwd, command)) t.start() 111-配置IP地址
RHEL7主机有四块网卡,名为eth0/eth1/eth2/eth3。为四块网卡配置IP地址。
#!/usr/bin/python3import sysimport redef configip(fname, ip_addr, if_ind): content = """TYPE=EthernetBOOTPROTO=noneNAME=eth%sDEVICE=eth%sONBOOT=yesIPADDR=%sPREFIX=24""" % (if_ind, if_ind, ip_addr) with open(fname, 'w') as fobj: fobj.write(content)def check_ip(ip_addr): # 判断IP地址是不是X.X.X.X格式 m = re.match(r'(\d{1,3}\.){3}\d{1,3}$', ip_addr) if not m: return False return Truedef show_menu(): prompt = """Configure IP Address:(0) eth0(1) eth1(2) eth2(3) eth3Your choice(0/1/2/3): """ try: if_ind = raw_input(prompt).strip()[0] except: print 'Invalid input.' sys.exit(1) if if_ind not in '0123': print 'Wrong Selection. Use 0/1/2/3' sys.exit(2) fname = '/etc/sysconfig/network-scripts/ifcfg-eth%s' % if_ind ip_addr = raw_input('ip address: ').strip() result = check_ip(ip_addr) if not result: print 'Invalid ip address' sys.exit(3) configip(fname, ip_addr, if_ind) print '\033[32;1mConfigure ip address done. Please execute "systemctl restart NetworkManager"\033[0m'if __name__ == '__main__': show_menu() 112-模拟字符串lstrip用法
思路:
1、取出字符串长度 2、通过range和字符串长度得到字符串下标 3、找到非空字符串下标,剩余部分取切片 4、如果字符串没有非空字符,返回空串whitesps = ' \r\n\v\f\t'def rmlsps(astr): for i in range(len(astr)): if astr[i] not in whitesps: return astr[i:] else: # 所有字符均为空,循环正常结束,返回空串 return ''if __name__ == '__main__': print(rmlsps(' \thello ')) 113-模拟字符串rstrip用法
思路参考 112-模拟字符串lstrip用法
whitesps = ' \r\n\v\f\t'def rmrsps(astr): for i in range(-1, -len(astr), -1): # 自右向左,下示为负 if astr[i] not in whitesps: return astr[:i + 1] # 结束下标对应的字符不包含,所以加1 else: return ''if __name__ == '__main__': print(rmrsps('')) print(rmrsps(' \thello ')) 114-百鸡百钱问题
我国古代数学家张丘建在《算经》一书中提出的数学问题:鸡翁一值钱五,鸡母一值钱三,鸡雏三值钱一。百钱买百鸡,问鸡翁、鸡母、鸡雏各几何?
思路: 1、答案不只一个 2、如果全是公鸡i,最多100/5只 3、如果全是母鸡j,最多100/3只 4、如果全是小鸡k,100块钱,可以买300只;但,所有的鸡最多是100只 5、鸡的数目i+j+k==100 6、鸡的价钱i * 5 + j * 3 + k / 3 == 100for i in range(100//5 + 1): # //表示只留商,不要小数,舍弃余数 for j in range(100//3 + 1): for k in range(100): if i + j + k == 100 and i * 5 + j * 3 + k // 3 == 100: print('公鸡:%s, 母鸡:%s,小鸡:%s' % (i, j, k)) 115-fork子进程解析
当使用fork编写多进程的程序时,应该想清楚父子进程的工作各是什么。比如,让父进程生成子进程,子进程做具体的工作。当子进程执行完毕后,需要exit退出。如果不退出,它仍然在循环结构中,子进程还会再生成子进程。
以下代码:import osfor i in range(3): pid = os.fork() if not pid: print('hello') 执行时,屏幕上将打印7行hello。
分析如下:
116-钉钉机器人
在很多情况下,如果能发消息到手机是一个非常实用的功能。比如,zabbix监控报警,可以采用执行脚本,向手机发送报警消息。
阿里巴巴的钉钉可以很方便的向用户发送消息,实际上就是建一个群,在群里面创建一个机器人。发消息就是通过脚本让机器人在群里说话而已。 在群里创建机器人并设置,可以通过钉钉网页版,网址为:https://im.dingtalk.com/ 创建机器人的步骤如下: 1、在钉钉群聊的右上角点机器人 2、点击“+”添加机器人
2、点击“+”添加机器人  3、选择机器人类型
3、选择机器人类型  4、给机器人起名
4、给机器人起名  5、将webhook内容保存下来,备用
5、将webhook内容保存下来,备用  编写脚本dingtalk.py:
编写脚本dingtalk.py: #!/usr/bin/python3import jsonimport requestsimport sysdef send_msg(url, reminders, msg): headers = {'Content-Type': 'application/json;charset=utf-8'} data = { "msgtype": "text", # 发送消息类型为文本 "at": { "atMobiles": reminders, "isAtAll": False, # 不@所有人 }, "text": { "content": msg, # 消息正文 } } r = requests.post(url, data=json.dumps(data), headers=headers) return r.textif __name__ == '__main__': msg = sys.argv[1] reminders = ['15055667788'] # 特殊提醒要查看的人,就是@某人一下 url = 此处填写上面第5步webhook的内容 print(send_msg(url, reminders, msg)) 发送消息进行测试:
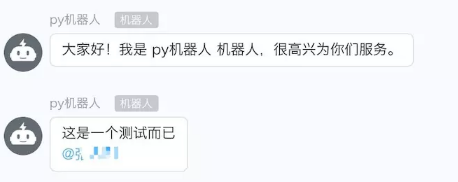
# python3 dingtalk.py "这是一个测试而已"
收到的消息如下:
117-可变与不可变对象的效率
python是一种解释型的语言,执行效率要比C这样的编译型语言差得多,但是也应该注意它的效率。
python的各种数据类型,按更新模型可以分为可变类型(如列表、字典)和不可变类型(如数字、字符串和元组)。多使用可变类型,它的执行效率比不可变类型要高。 在《37-生成密码/验证码》中,将结果保存到了一个名为 result 的变量中。result 是字符串,字符串不可变,所以python在工作时,首先要申请一段内存储 result 的初值(空串’’),随机取得一个字符后(如’a’),result += 'a’实际上是要重新申请一个新的内存,把新字符串存储进去。如此往复,有几次循环,就要重新分配几次内存。 如果变量 result 使用列表,只需要为其分配一次内存即可,因为列表是可变的。代码可以更改为以下样式:from random import choiceimport stringall_chs = string.ascii_letters + string.digits # 大小写字母加数字def gen_pass(n=8): result = [] for i in range(n): ch = choice(all_chs) result.append(ch) return ''.join(result)if __name__ == '__main__': print(gen_pass()) print(gen_pass(4)) print(gen_pass(10))
118-ip地址与10进制数的转换
我们先写个ping命令看看结果:
bogon:~ zhangzhigang$ ping -c2 2130706433PING 2130706433 (127.0.0.1): 56 data bytes64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=0.043 ms64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.080 ms--- 2130706433 ping statistics ---2 packets transmitted, 2 packets received, 0.0% packet lossround-trip min/avg/max/stddev = 0.043/0.061/0.080/0.018 msbogon:~ zhangzhigang$
当我们ping数字2130706433时,从127.0.0.1返回结果。为什么是这样呢?
IP地址是个32位的二进制数,表示成点分10进制,只是为了方便,如果把这32位二进制数转成10进制数,计算机也是认识的。 咱们就编写一个将10进制数转成2进制的代码吧。 思路: 1、仔细分析,IP地址的四个10进制数,实际上就是256进制 127.0.0.1 <=> 127 * 2563 + 0 * 2562 + 0 * 2561 + 1 * 2560 2、10进制数除以256,余数就是IP地址右侧的数字,商继续除256即可 具代体码如下:def int2ip(digit): result = [] for i in range(4): digit, mod = divmod(digit, 256) result.insert(0, mod) return '.'.join(map(str, result))if __name__ == '__main__': print(int2ip(2130706433))
map函数用法,参见《70-匿名函数和map》
119-比较文件的差异
比较两个文件的差异,可以直接使用vim。
# vim -d /etc/passwd /etc/passwd-
python标准库提供了一个difflib,可以进行文件的比较,并且可以生成网页的形式。
import difflib import webbrowser import sys import string import os from random import choicedef rand_chs(n=8): # 默认生成8个随机字符
all_chs = string.ascii_letters + string.digits result = [choice(all_chs) for i in range(n)] return ‘’.join(result)函数接收两个相似的文件名,返回HTML形式的字符串
def make_diff(lfile, rfile): d = difflib.HtmlDiff() # 将两个文件分别读到列表中 with open(lfile) as fobj: ldata = fobj.readlines() with open(rfile) as fobj: rdata = fobj.readlines() return d.make_file(ldata, rdata) # 返回HTML格式内容if __name__ == '__main__': try: lfile = sys.argv[1] rfile = sys.argv[2] except IndexError: print('Usage: %s file1 file2' % sys.argv[0]) sys.exit(1) if not os.path.isfile(lfile): print('No such file:', lfile) sys.exit(2) if not os.path.isfile(rfile): print('No such file:', rfile) sys.exit(3) data =make_diff(lfile, rfile) # 以下只是为说明内容增加中文显示,非必须项 data = data.replace(';Added', ';Added(增加)') data = data.replace('>Changed', '>Changed(改变)') data = data.replace('>Deleted', '>Deleted(被删除)') data = data.replace('(f)irst change', '(f)irst change【第一处变更】') data = data.replace('(n)ext change', '(n)ext change【下一处变更】') data = data.replace('(t)op', '(t)op【回到顶部】') html_file = '/tmp/%s.html' % rand_chs() # 用随机字符生成文件名 with open(html_file, 'w') as fobj: fobj.write(data) webbrowser.open_new_tab('file:///%s' % html_file) # 使用浏览器打开文件 120-打造vim为python IDE
pycharm之类的IDE很好,但是不能在无图形的终端下使用,另外它们是“重量级选手”。如果偶尔需要vim编辑python程序,能让vim支持python的语法提示不是更好!
实际上,vim支持python提示,就是把python以及各种各样模块的常用指令都写到一个字典里。 操作步骤如下: 1、创建vim插件工作目录bogon:~ zhangzhigang$ mkdir -p ~/.vim/bundle/
2、下载插件
$ cd ~/.vim/bundle/bogon:bundle zhangzhigang$ git clone https://github.com/rkulla/pydiction.gitbogon:bundle zhangzhigang$ lspydiction
3、将pydiction目录中的after目录拷贝到 /.vim/目录。当vim执行时,会自动执行/.vim/目录中的内容
bogon:bundle zhangzhigang$ cp -r pydiction/after/ ~/.vim/
4、修改vim配置,设置打开以.py结尾的文件,按tab可以支持python语法补全
bogon:bundle zhangzhigang$ vim ~/.vimrcfiletype plugin onlet g:pydiction_location = '~/.vim/bundle/pydiction/complete-dict'set aiset etset ts=4
5、测试,注意文件名必须是以.py结尾,否则没有代码补全
bogon:bundle zhangzhigang$ vim a.pyimp
121-配置zabbix通过钉钉机器人报警
钉钉机器人的设置,参见《116-钉钉机器人》
zabbix服务器监控到异常,可以通过各种方式发送报警消息。配置步骤如下: 1、创建报警脚本[root@node ~]# vim /usr/local/share/zabbix/alertscripts/dingalert.py#!/usr/bin/env pythonimport jsonimport requestsimport sysdef send_msg(url, remiders, msg): headers = {'Content-Type': 'application/json; charset=utf-8'} data = { "msgtype": "text", "at": { "atMobiles": remiders, "isAtAll": False, }, "text": { "content": msg, } } r = requests.post(url, data=json.dumps(data), headers=headers) return r.textif __name__ == '__main__': msg = sys.argv[1] remiders = [] url = '钉钉机器人的URL' print(send_msg(url, remiders, msg))[root@node ~]# chmod +x /usr/local/share/zabbix/alertscripts/dingalert.py 2、添加报警媒介
 3、配置用户可以使用脚本报警
3、配置用户可以使用脚本报警 



 4、配置触发动作
4、配置触发动作 


 5、触发报警条件。如,本例中/boot分区空间不足20%将会发生报警。
5、触发报警条件。如,本例中/boot分区空间不足20%将会发生报警。 [root@node ~]# dd if=/dev/zero of=/boot/t.img bs=1M count=800[root@node ~]# df -h /boot/文件系统 容量 已用 可用 已用% 挂载点/dev/vda1 1014M 961M 54M 95% /boot
6、查看动作日志及钉钉消息


122-python交互解释器tab补全功能
进入python交互解释器后,按tab键默认是缩进功能,而不是代码补全。为了实现代码补全,可以采用如下操作:
1、创建指令补全文件[root@666 ~]# vim /usr/local/bin/tab.pyfrom rlcompleter import readlinereadline.parse_and_bind('tab: complete') 2、配置环境变量,在~/.bashrc中追加以下内容
[root@666 ~]# vim ~/.bashrcexport PYTHONSTARTUP='/usr/local/bin/tab.py'
3、source生效
[root@666 ~]# source ~/.bashrc
4、进入python解释器验证:
[root@666 ~]# python3>>> pr# 可实现语法提示>>> pri # 补全
123-进度条
经常有同学希望实现进度条的功能。这个功能可以采用现有的模块来实现,这里我来介绍一个简单的进度条模块tqdm。
首先用pip安装tqdm:[root@666 ~]# pip install tqdm
tqdm的应用,只要给它封装上一个迭代器即可:tqdm(iterator)
先实现一个简单的进度条:[root@666 ~]# vim /tmp/process_bar.pyfrom tqdm import tqdmimport timefor i in tqdm(range(10)): time.sleep(1)[root@room8pc16 ~]# python3 /tmp/process_bar.py30%|█████████████▏ | 3/10 [00:03<00:07, 1.00s/it]
124-带进度条的文件拷贝
在【123-进度条】中介绍了tqdm进度条,那么怎么把它与其他代码结合起来使用呢?
下面举一个在拷贝过程中增加进度条的示例。 首先,确定拷贝文件时每次从源文件读取数据的长度length,如4096字节。 然后,确定需要从源文件读取多少次。读取次数用源文件的总大小除以length即可得到。源文件大小可以这样获得:[root@666 ~]# python3>>> import os>>> os.stat('/bin/ls')os.stat_result(st_mode=33261, st_ino=134897105, st_dev=64768, st_nlink=1, st_uid=0, st_gid=0, st_size=117616, st_atime=1545969810, st_mtime=1447997566, st_ctime=1494055224)# 上面输出的st_size就是文件大小>>> size = os.stat('/bin/ls').st_size>>> print(size)117616 获取了文件的大小,接下来求出读取次数times:
>>> length = 4096>>> times, extra = divmod(size, length) # 同时获取商和余数>>> if extra:... times += 1 # 如果余数不为0,次数加1
有了上面的思路,下面看看完整的代码:
[root@666 ~]# vim /tmp/cp.pyimport osimport sysfrom tqdm import tqdmdef copy(src_fname, dst_fname, length=4096): size = os.stat(src_fname).st_size times, extra = divmod(size, length) if extra: times += 1 with open(src_fname, 'rb') as src_fobj: with open(dst_fname, 'wb') as dst_fobj: for i in tqdm(range(times)): data = src_fobj.read(length) dst_fobj.write(data)if __name__ == '__main__': copy(sys.argv[1], sys.argv[2])
125-图灵聊天机器人
纯手工从零开始打造一个机器人并不容易,但是我们可以调用现成的机器人啊!
首页,到【图灵机器人】注册一个帐号。 注册完毕后,登陆进去就可以看到一个“创建机器人”的按钮,点击创建一个机器人: 里面的内容都只是随手一填而已。 关键的是要把这个apikey记下来:
里面的内容都只是随手一填而已。 关键的是要把这个apikey记下来:  剩下的事就简单了,打开“帮助中心”看看把什么数据传过去就搞定了:
剩下的事就简单了,打开“帮助中心”看看把什么数据传过去就搞定了:  代码如下:
代码如下: zhangzhigangdeMacBook-Pro: zhangzhigang$ vim tuling_robot.pyimport requestsimport jsondef tuling_reply(url, apikey, msg): data = { # 这个是在帮助手册上直接复制过来的 "reqType":0, "perception": { "inputText": { "text": msg }, "selfInfo": { "location": { "city": "北京", "province": "北京", "street": "天坛北门" } } }, "userInfo": { "apiKey": apikey, # 你注册的apikey "userId": "anystr" # 随便填点 } } headers = {'content-type': 'application/json'} # 必须是json r = requests.post(url, headers=headers, data=json.dumps(data)) return r.json()if __name__ == '__main__': apikey = '填入机器人的apikey' url = 'http://openapi.tuling123.com/openapi/api/v2' while True: msg = input('(输入quit结束)> ').strip() if not msg: continue if msg == 'quit': break reply = tuling_reply(url, apikey, msg) print(reply["results"][0]["values"]["text"]) # 可以直接打印reply 运行的结果如下:
zhangzhigangdeMacBook-Pro: zhangzhigang$ python3 tuling_robot.py(输入quit结束)> 今天天气怎么样北京:周二 02月12日 (实时:-3℃),小雪转多云 东风微风,最低气温-7度,最高气温-3度(输入quit结束)> 吃了吗?还没吃呢,你打算请吗(输入quit结束)> 我请客,你出钱掏钱多没意思,你直接发红包吧。(输入quit结束)> quit
转载地址:http://zenwi.baihongyu.com/